Del OCR a los LLM: El Nuevo Paradigma de la Inteligencia Documental
El Reconocimiento Óptico de Caracteres (OCR) se ha convertido, desde hace décadas, en un componente esencial para la digitalización de documentos y la automatización de procesos. Sin embargo, la necesidad de comprender realmente el texto —y no solo extraerlo— ha impulsado la aparición de nuevas soluciones basadas en Modelos de Lenguaje de Gran Tamaño (LLM). En la actualidad, tecnologías como Azure OpenAI han redefinido las posibilidades de la inteligencia documental, haciendo énfasis en una comprensión semántica más profunda y en la facilidad de integración con sistemas empresariales.
A lo largo de este artículo, exploraremos la evolución del OCR tradicional, sus limitaciones y cómo los LLM están potenciando un salto cualitativo. Además, veremos la importancia de la automatización inteligente dentro del ecosistema de Microsoft, con referencias a servicios como Azure AI Foundry, Document Intelligence y Power Automate, así como algunas consideraciones técnicas clave para su adopción.
1. Limitaciones Clásicas del OCR
Los sistemas de OCR extraen caracteres y palabras de imágenes o documentos escaneados. Aun con mejoras constantes, estos presentan tres grandes restricciones:
Falta de Contexto Semántico
- El OCR “lee” caracteres, pero no relaciona ni interpreta su significado dentro de un texto más amplio. En un contrato legal, por ejemplo, reconoce la palabra “penalización” pero no sabe si está ligada a un plazo o a una cláusula específica.
Dependencia de la Calidad de la Fuente
- Factores como el deterioro de la página, la iluminación o el uso de fuentes poco convencionales generan inexactitudes. Aunque existen técnicas de preprocesamiento, las tasas de error pueden aumentar considerablemente si la calidad es baja.
Limitaciones en Estructuras Complejas
- Formularios con varios campos, tablas desalineadas o documentos con diseños no estándar siguen requiriendo una configuración o entrenamiento más elaborado para extraer los datos correctamente.
2. El Potencial de los LLM y la Nueva Inteligencia Documental
Los Modelos de Lenguaje de Gran Tamaño suponen un avance notable porque no se detienen en la extracción de texto, sino que analizan y comprenden su significado. Esta evolución abre la puerta a una inteligencia documental mucho más sofisticada:
2.1 Procesamiento Semántico y Corrección de Errores
Los LLM pueden:
- Corregir de forma automática los errores provenientes del OCR, basándose en probabilidades lingüísticas y contexto.
- Identificar entidades o términos clave (nombres, fechas, cláusulas, etc.), aportando metadatos críticos para cualquier flujo de automatización.
- Relacionar partes del texto, ofreciendo una visión global y estructurada del documento.
Ejemplo Práctico
En la digitalización de historiales médicos, un modelo de lenguaje puede inferir campos incompletos (por ejemplo, un diagnóstico omitido) o corregir términos clínicos mal escaneados, gracias a su amplio conocimiento de vocabulario.
2.2 Integración Multimodal
Algunos modelos admiten análisis tanto de texto como de imágenes, lo que reduce la complejidad de los pipelines. En lugar de orquestar varias herramientas, los documentos (incluyendo diagramas, gráficos o anotaciones) pueden procesarse de forma conjunta, obteniendo así una comprensión más rica.
2.3 Mejora Constante con Retroalimentación
Otro aspecto interesante es la capacidad de los LLM para aprender de la retroalimentación continua. Con un conjunto de ejemplos corregidos o validados por usuarios, se puede ajustar el modelo a un dominio concreto (legal, financiero, etc.) y refinar su precisión con el tiempo.
3. Arquitectura Híbrida: Uniendo OCR y LLM
A pesar de las ventajas que brindan los LLM, el OCR sigue siendo el punto de partida para extraer texto de documentos escaneados. Una aproximación eficaz en entornos empresariales suele darse a través de arquitecturas híbridas:
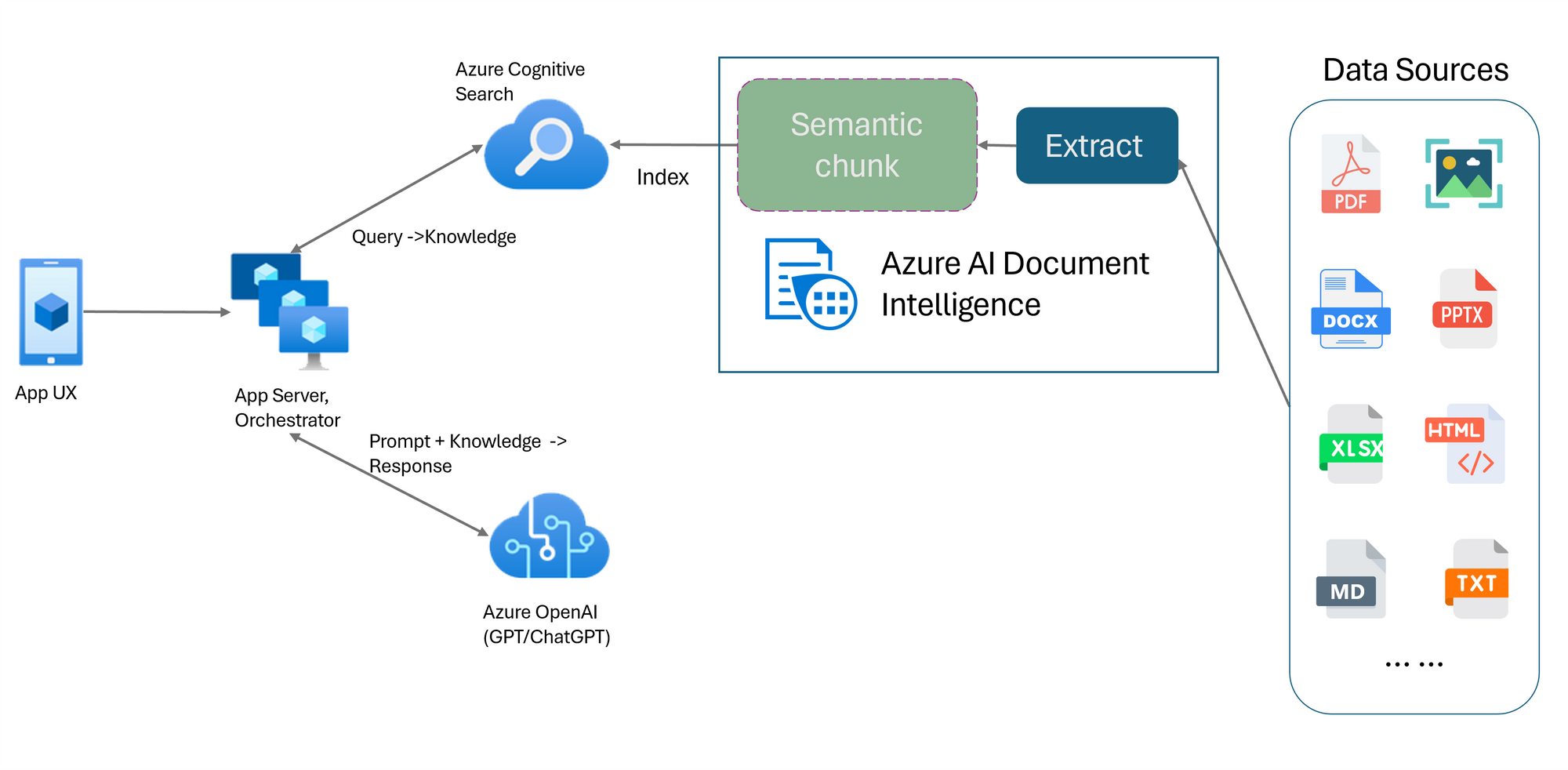
Extracción Base con OCR
- Se emplean servicios de Microsoft enfocados en el reconocimiento de texto y la estructuración de documentos, como Document Intelligence (hay muchos otros, pero es el que mas he utilizado) que ofrecen una primera capa de datos.

Procesamiento Semántico con LLM
- Un modelo como GPT-4o (GPT-40 mini para este cometido es muy válido, además de mas barato), accesible en Azure OpenAI, analiza y enriquece los resultados, corrigiendo posibles errores y añadiendo contexto (fechas, relaciones entre cláusulas, etc.).
Orquestación y Automatización
- Herramientas como Power Automate pueden desencadenar flujos de trabajo basados en el resultado del LLM, ya sea para almacenar los datos en una base de datos, en un gestor documental como SharePoint, generar alertas o integrar con sistemas de back-office.
Caso de Uso
En la gestión de facturas, el OCR extrae datos elementales (proveedor, importe, fecha), mientras que el LLM valida su coherencia (por ejemplo, el cálculo de impuestos) y, si encuentra discrepancias, notifica al responsable correspondiente o genera un aviso en el ERP de la compañía.
4. Desafíos y Consideraciones Técnicas
Aunque la convergencia entre OCR y LLM presenta beneficios claros, es importante tener en cuenta varios aspectos:
Costes de Procesamiento
- El uso de modelos avanzados puede implicar mayores costes de cómputo. La nube de Microsoft ofrece elasticidad, pero es fundamental optimizar las cargas de trabajo y mantener un control de la facturación.
Entrenamiento de Dominio
- Para textos legales, médicos o financieros, se requiere adaptar el LLM mediante fine-tuning, lo que exige un conjunto de datos representativo y un proceso de validación minucioso. Esto da para un artículo entero. Próximamente hablaré de cuando debemos utilizar fine-tuning en los LLM's y cuando no.
Latencia en Flujos Críticos
- El procesamiento secuencial de OCR y LLM puede elevar la latencia. En aplicaciones donde la velocidad sea prioritaria (como verificación de documentos en línea), conviene diseñar pipelines eficientes y optimizar cada etapa.
Privacidad y Cumplimiento Normativo
- Procesar documentos sensibles (sanitarios, legales, etc.) implica salvaguardar la confidencialidad. Azure AI Foundry o las opciones de despliegue privado de Azure OpenAI pueden ayudar a cumplir con regulaciones locales e internacionales.
5. Futuro de la Automatización: Hacia los Agentes de IA
La tendencia apunta a la aparición de agentes de IA capaces de realizar tareas complejas, integrando:
- Reconocimiento de imágenes (OCR) como puerta de entrada para la digitalización.
- Modelos de lenguaje que comprendan las relaciones semánticas y extraigan conclusiones.
- Acciones automatizadas desencadenadas en función de esa comprensión (generar reportes, actualizar bases de datos o incluso tomar decisiones administrativas simples).
Este nuevo paradigma posibilita sistemas más ágiles y autónomos, en los que los profesionales humanos se centran en tareas de mayor valor, mientras la IA se encarga de las labores repetitivas o de gran volumen.
6. Recomendaciones para empresas que buscan escalar
Diseño de Pipelines Híbridos y Flexibles
- Empezar con un OCR sólido y, gradualmente, incorporar capas de inteligencia semántica con LLM, ajustando la complejidad del modelo a las necesidades reales.
Uso de Servicios en la Nube de Forma Selectiva
- Servicios como Azure OpenAI permiten acceder a grandes modelos con alta disponibilidad. De igual forma, contar con opciones de despliegue en entornos privados ofrece control adicional sobre los datos.
Automatización y Orquestación
- Herramientas como Power Automate agilizan la creación de flujos de trabajo sin requerir un gran desarrollo adicional.
- Integrar validaciones y retroalimentación en estos flujos para enriquecer el modelo de forma continua.
Monitoreo y Gobernanza de Datos
- Establecer una política de calidad de datos, con mediciones de exactitud y reglas de cumplimiento. Así, se garantiza que los resultados de la IA sean fiables y auditables.
7. Conclusión
El OCR tradicional mantiene su relevancia como puerta de entrada a la digitalización de documentos, pero la auténtica transformación llega con la incorporación de Modelos de Lenguaje que comprenden y contextualizan el texto. De la mano de soluciones como Azure OpenAI, Document Intelligence o Power Automate, las organizaciones pueden construir ecosistemas automatizados más ágiles, capaces de evolucionar conforme cambian los requisitos del negocio.
El futuro se vislumbra con agentes de IA que combinen reconocimiento visual, procesamiento de lenguaje natural y capacidad de actuación autónoma. Quienes adopten este modelo híbrido—OCR más LLM— se posicionarán para optimizar costes, reducir la tasa de errores y, sobre todo, extraer el máximo valor de sus datos en un entorno cada vez más competitivo y orientado a la eficiencia.