

MuRAG: Generación de Lenguaje Multimodal
En un avance impresionante dentro del campo del Procesamiento del Lenguaje Natural (NLP) y la inteligencia artificial, diversos investigadores han introducido un nuevo modelo denominado MuRAG (Multimodal Retrieval-Augmented Generator), que promete revolucionar la manera en que las máquinas comprenden y generan contenido a partir de una rica mezcla de texto e imágenes. Este modelo, presentado por Wenhu Chen, Hexiang Hu, Xi Chen, Pat Verga, William W. Cohen, y su equipo, se destaca por su capacidad para integrar conocimientos de múltiples modalidades, abriendo nuevas vías para aplicaciones de inteligencia artificial más intuitivas y comprensibles.
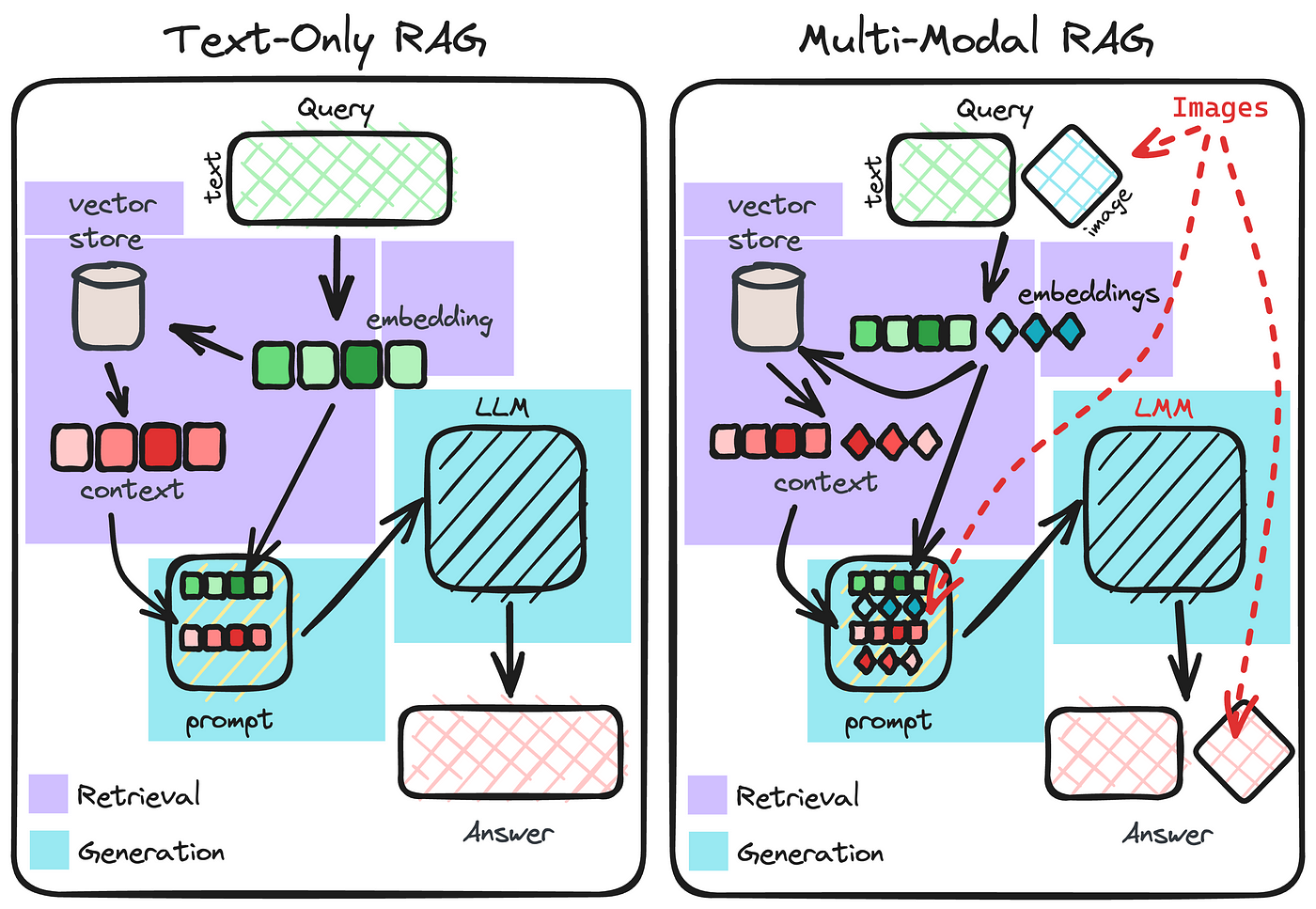
La Necesidad de Multimodalidad
En la actualidad, nos comunicamos de manera multimodal: combinamos texto, imágenes, y a veces sonidos para expresar ideas complejas. Tradicionalmente, los modelos de NLP se han centrado en el texto, dejando de lado la riqueza de información disponible en otros formatos. MuRAG aborda esta brecha integrando de forma efectiva el conocimiento visual en el proceso de generación de lenguaje, permitiendo que el sistema acceda a un índice externo no parametrizado de memoria multimodal durante la generación de texto.
¿Cómo Funciona MuRAG?
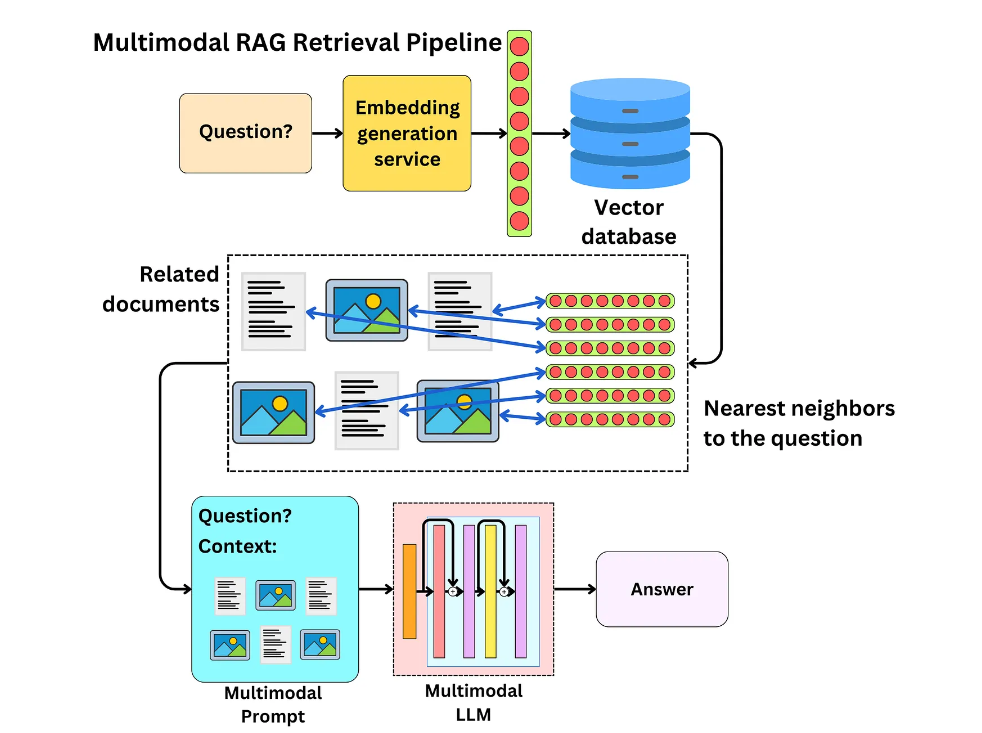
El modelo MuRAG, abreviatura de Multimodal Retrieval-Augmented Generator, representa una innovación en el campo del Procesamiento de Lenguaje Natural (NLP) y la visión por computador al fusionar información textual y visual para mejorar la generación de respuestas en tareas de preguntas y respuestas (Q&A). En el whitepaper de Wenhu Chen y sus colaboradores, se presenta una metodología detallada que subraya cómo MuRAG extiende las capacidades de modelos previos de generación de lenguaje, como RAG (Retrieval-Augmented Generation) y REALM (Retrieval-Enhanced Language Model), incorporando un componente multimodal en el proceso de recuperación de información.
Arquitectura Básica
MuRAG se basa en una arquitectura Transformer, que es un estándar en muchos modelos de lenguaje debido a su eficacia en la captura de relaciones complejas en los datos. La innovación clave de MuRAG reside en su capacidad para acceder a una memoria externa no parametrizada durante la generación de lenguaje, que no solo comprende texto, sino también imágenes. Esto permite al modelo recuperar y utilizar de manera efectiva información multimodal para generar respuestas más precisas y contextualizadas.
Proceso de Recuperación Multimodal
El proceso comienza cuando MuRAG recibe una consulta, que puede ser una pregunta o un prompt que requiere una respuesta generativa. El modelo entonces realiza una búsqueda en su memoria externa no parametrizada para encontrar los fragmentos de información más relevantes, tanto textuales como visuales, que puedan ayudar a generar la respuesta adecuada.
- Recuperación de Información: Utiliza un mecanismo de atención para evaluar la relevancia de diferentes piezas de información en la memoria externa con respecto a la consulta dada.
- Selección Multimodal: MuRAG evalúa y selecciona contenido textual y visual basándose en su relevancia para la consulta. Esto se logra a través de un proceso de ponderación que considera la importancia relativa de la información recuperada de diferentes modalidades.
- Generación de Respuestas: Una vez seleccionada la información relevante, MuRAG la integra para generar una respuesta coherente y contextualizada. Esto se logra mediante la decodificación de la información recuperada, combinando efectivamente los elementos textuales y visuales para formular una respuesta.
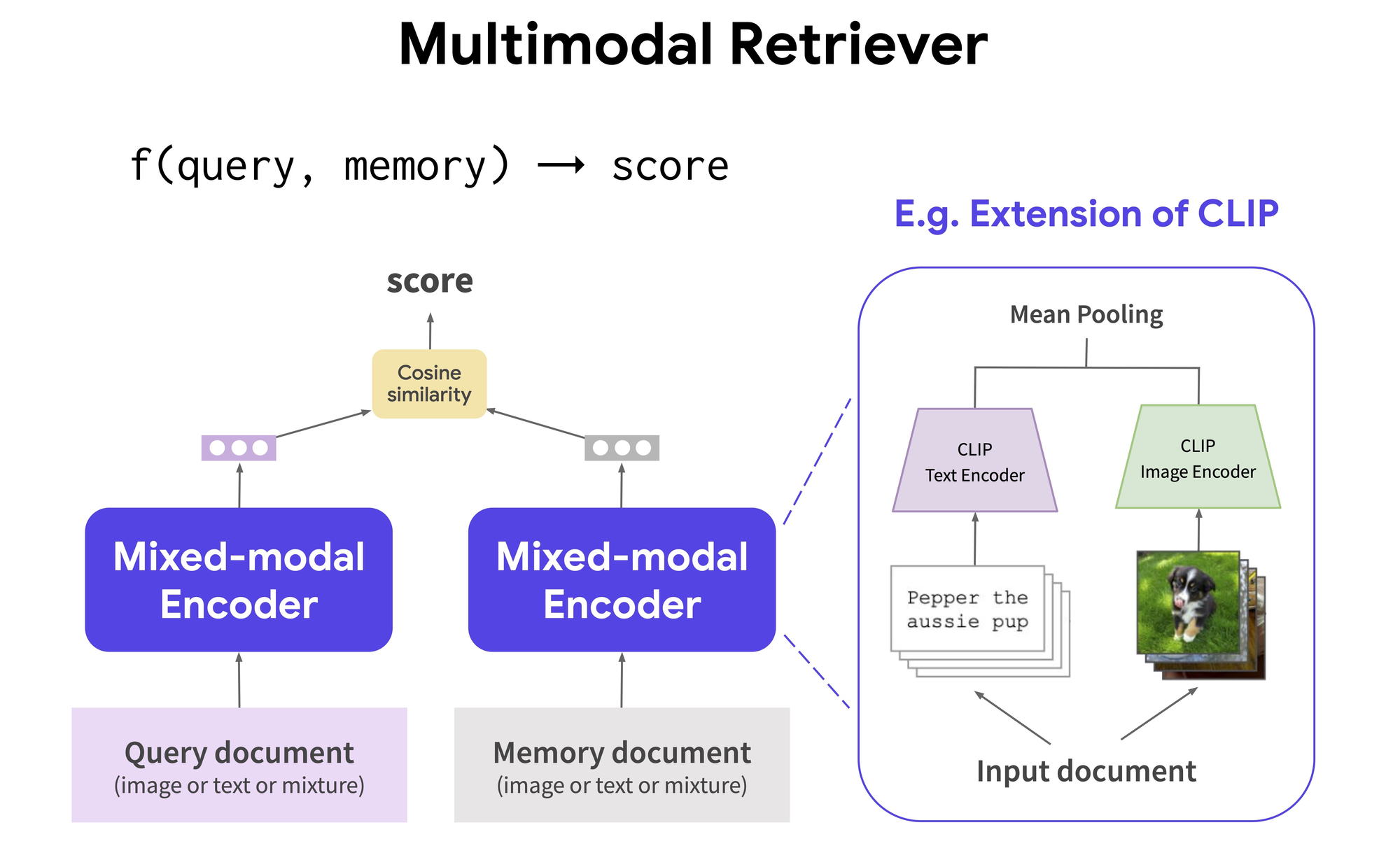
Entrenamiento y Optimización
Para optimizar su rendimiento, MuRAG se preentrena y afina en un conjunto de tareas específicas que requieren comprensión multimodal, como el Q&A abierto sobre imágenes y texto. Este proceso implica ajustar los parámetros del modelo para mejorar su capacidad de recuperar, seleccionar y generar información basada en las entradas multimodales proporcionadas durante la fase de entrenamiento.
Contribuciones Clave y Resultados
El whitepaper detalla cómo MuRAG logra mejoras significativas en precisión y relevancia en comparación con modelos que solo consideran información textual. Los autores demuestran a través de experimentos en diversos conjuntos de datos que MuRAG puede superar a los modelos actuales en tareas que requieren razonamiento a partir de múltiples fuentes de información.
- Rendimiento Superior en Tareas de Q&A: Los experimentos realizados demuestran que MuRAG supera a los modelos basados únicamente en texto en tareas de Q&A que involucran razonamiento multimodal. Esto incluye una mejora en la precisión de las respuestas y en la capacidad de proporcionar explicaciones detalladas y contextualmente relevantes.
- Generalización a Diferentes Dominios: MuRAG ha mostrado una notable capacidad para adaptarse y generalizar a través de diferentes conjuntos de datos y dominios, lo que subraya su potencial como herramienta versátil para el procesamiento de información multimodal.
- Integración Efectiva de Información Multimodal: Los resultados también destacan la capacidad de MuRAG para integrar de manera efectiva y cohesiva información de múltiples modalidades, lo que resulta en generaciones de lenguaje que son no solo precisas sino también más informativas y útiles para los usuarios finales.
Aplicaciones y Beneficios
Las implicaciones de este avance son muchas. En el ámbito educativo, MuRAG podría mejorar los sistemas de tutoría virtual, ofreciendo explicaciones más ricas y contextualizadas. En el sector de los medios de comunicación, facilitaría la creación de contenido que combine de manera efectiva elementos visuales y textuales, mejorando la narración de historias digitales. Además, en el campo de la asistencia médica, podría ayudar a analizar y sintetizar información de historiales médicos y resultados de pruebas diagnósticas, proporcionando insights más completos para el apoyo a la toma de decisiones.
Desafíos y Futuro
A pesar de estas investigaciones, integrar eficazmente múltiples modalidades en la generación de lenguaje presenta desafíos técnicos importantes, como la necesidad de comprender y procesar efectivamente grandes volúmenes de datos visuales y textuales. Además, la evaluación de la relevancia y la precisión de la información recuperada de múltiples fuentes sigue siendo un área de investigación activa. Sin embargo, el equipo detrás de MuRAG está liderando el camino hacia superar estos obstáculos, marcando el comienzo de una nueva era en la inteligencia artificial multimodal.
Conclusión
MuRAG representa un paso significativo hacia el objetivo de crear sistemas de inteligencia artificial que puedan entender y generar lenguaje de manera más humana, aprovechando la riqueza de información disponible en múltiples formatos. A medida que continuamos explorando las capacidades de estos modelos, nos acercamos cada vez más a máquinas que pueden comprender y comunicarse con nosotros de manera más natural e intuitiva.
Para aquellos interesados en explorar más a fondo los detalles técnicos y las aplicaciones potenciales de MuRAG, el whitepaper completo es un gran recurso. Puedes acceder al estudio completo de Wenhu Chen y colaboradores a través de este enlace: MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text, donde se detalla cómo este modelo está estableciendo nuevos estándares para el futuro de la generación de lenguaje y la inteligencia artificial.


